The joint study of the Yamagata University Institute of Nasca and IBM Japan, Ltd. (hereinafter, IBM Japan) has been published in the international academic journal “Journal of Archaeological Science“. The title of the paper is “Accelerating the discovery of new Nasca geoglyphs using deep learning“. This paper summarizes the technical methodology of the joint feasibility study announced in November 2019 and the results of subsequent research, including on-site surveys. Based on the feasibility study conducted in the northern part of the Nasca Pampa, the paper details the deep learning AI model used for the distribution survey of figurative geoglyphs which led to the discovery of four geoglyphs (humanoid, a pair of legs, fish, and bird), one of which (humanoid) was released in 2019. Importantly, the paper shows that deep learning technology enables accelerated identification of geoglyph candidates approximately 21 times faster than manual imagery analysis using the naked eye.
Background
The Yamagata University Institute of Nasca and IBM Japan have conducted a feasibility study using deep learning-based object detection techniques to discover figurative geoglyphs from high-resolution aerial photographs. Aerial photographs cover a vast area, and the traditional method of hunting for new geoglyph candidates by the naked eyes from photographs requires a substantial amount of time, posing a challenge in efficiency and scalability. To address the challenge we conducted a feasibility study using deep learning to accelerate discovery. The target area was the northern part of the Nasca Pampa, where line-type figurative geoglyphs are concentrated. Due to the requirement of detecting unconfirmed geoglyph candidates, careful consideration and ingenuity were needed in order to train a deep learning object detection model using training data of very limited quality and quantity.
Research Methods and Results
The known geoglyph patterns are unique and complex. Therefore, it is likely that new geoglyphs will not have the same design as the existing ones. It is difficult to find new geoglyphs using deep learning object detection models trained only on known geoglyphs, as they may not be able to find features that do not exist in the training data. To address this issue, we divided the known geoglyphs into relatively simple pictorial elements and used them as training data to create an object detection model. We hypothesized that there would be similar elements in new geoglyphs and the method may improve the generalization performance (the ability to detect new geoglyphs on previously unseen data) by focusing on capturing these elements rather than the entirety of geoglyphs.
In addition, the size of the known line-type figurative geoglyphs varied from approximately 10 to 300 meters, which posed another challenge in detecting geoglyphs. To address this issue, we first cropped the original images at multiple scales and then resized the cropped images to the same size for both the object detection model training phase and inference phase. This approach allowed us to attempt the detection of geoglyphs of different sizes.
Furthermore, the number of line-type figurative geoglyphs in the northern part of the Nasca Pampa that could be used as training data in this study was limited to 21. Ideally, deep learning requires thousands of training data points, therefore using these geoglyphs as training data has an issue of data scarcity. To address this issue, we increased the number of training data to 307 by dividing the geoglyphs into elements and cropping images at different scales, as mentioned earlier.
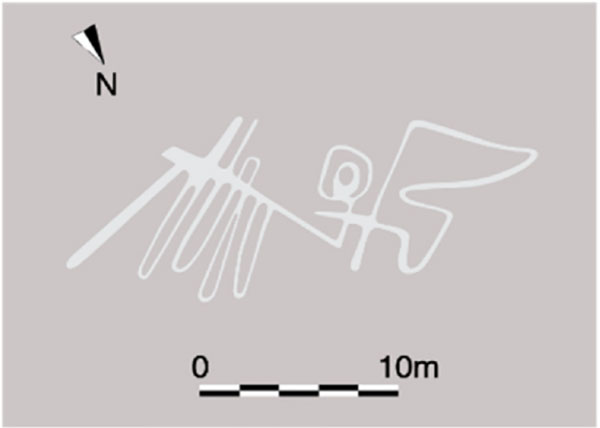
Using the object detection model created with these innovative measures, we attempted to detect geoglyphs from aerial photographs. We were able to confirm that the elements were detected from several known geoglyphs that were not used for the training data, indicating the effectiveness of our method. We then carefully reviewed the detection results to create new geoglyph candidates and utilized them in subsequent field surveys. As a result, four geoglyphs were discovered in the northern parte of the Nasca Pampa: a humanoid, a pair of legs, a fish, and a bird. The humanoid geoglyph (5m) was released in November 2019. On the other hand, the geoglyphs of legs (78m), fish (19m), and bird (17m) are included in the 358 geoglyphs identified by 2022, but their photographs and illustrations are published for the first time in this academic paper.
Furthermore, by using deep learning technology, we were able to identify geoglyph candidates approximately 21 times faster than with the naked eye alone.
Future Prospects
Following the success of this feasibility study, we are collaborating with IBM T. J. Watson Research Center to conduct a large scale AI-based distribution survey of geoglyphs across the entire Nasca Pampa. In addition, we plan to work with the Ministry of Culture of Peru to implement activities aimed at protecting the geoglyphs discovered using AI.
Notes
- Deep Learning
Deep learning is a method of machine learning that builds and trains neural networks, which are inspired by the interconnectedness of nerve cells in brains, to enable computers to learn the features from large amounts of data and to subsequently make predictions or decisions. It demonstrates high performance in tasks such as image recognition, speech processing, and natural language processing. Due to the need for fast and efficient computing infrastructure to process and learn from a large amount of data, we used an IBM Power server, which is suitable for deep learning workloads in this feasibility study. - Object Detection through Deep Learning
Object detection through deep learning automatically identifies specific classes of objects from images and determines their location, size, and classification. It is similar to the process humans use when detecting things like “dogs” or “cats,” but in this case, the computer does it. Deep learning models learn from (typically) a large amount of image data to understand the hierarchical features of objects. Based on such learning, they acquire the ability to accurately detect objects that appear in new images. - Training Data
The training data for object detection consists of a large collection of images that have been pre-labeled with the location, size, and classification of the objects (for example, dogs or cats).




